
Answering the "W"s and "H" of Edge AI
WHAT is Edge AI?
Edge AI, as the terms speaks for itself, is the AI technology integrated at the edge, i.e., closer to the user rather than hosted on the cloud.It refers to deployment and execution of AI algorithms directly on edge devices (microcontrollers, microprocessors, mobile phones, cameras, IoT sensors etc.)– without needing to communicate constantly with the cloud.
WHY Edge AI?
Traditional approaches of AI integration put forth the following limitations:
- Long Distance Cloud Communication: Cloud AI requires data to be sent over the internet to remote servers for processing, resulting in high latency.
- Privacy and Integrity risks: Transmitting sensitive data over clpoud increases the risk of data breachesand privacy violations.
- Cost: Uploding data to cloud consumes significant bandwidth and incurs high computational costs, especially at scale.
- Persistent improvement requirement: continuous changes with respect to updates and features contribute to the increased computation and maintenance costs.
- No real time insights: Real time data monitoring or insights is difficult on cloud AI due to long distance transmissions , lag and noice interferences in the signals.
These limitations are overcome by implementation of new technology called Edge AI. These are done as follows:
- Low Latency : Real – time decision-making without delays caused by cloud round trips.
- Improved privacy: Sensitive data says stays local, reducing risks of exposure.
- Reduced Bandwidth Usage : Less need to transmit raw data to the cloud hence reducing the clud costs.
- Offline Capability: works even without internet access. It has capability to work in offline state hence removing the internet dependency of the netwrok.
- Lower Operational Costs : since the reliance on cloud network is reduced, computational cost of cloud network is reduced to a great extent.
What is NXP EiQ Platform
The NXP® eIQ® artificial intelligence (AI) software development environment enables the use of ML algorithms on NXP microcontrollers and microprocessors, including i.MX RT crossover MCUs, IMX family application processors and S32K3 MCU’s
eIQ AI software includes a ML workflow tool called eIQ Toolkit, along with inference engines, neural network compilers and optimized libraries.
Now let’s breakdown each of the above keyword’s highlighted in depth to understand what exactly is eIQ AI toolkit.
( These keyword’s should be well explained in previous edge ai blog)
ML Workflow tool
- At first, ML workflow tool, which mean’s the systematic process for developing, training, evaluating and deploying machine learning models It encompasses a series of steps that guide practitioners through the entire lifecycle of a machine learning project from problem defination to solution deployment.
- Refernece: What Is a Machine Learning Workflow? | Pure Storage
- So eiQ toolkit is an ML work-flow tool for NXP MCUs.
Inference Engines
An inference engine is a software runtime environment that executes a trained and compiled machine learning model to produce predictions (also called inferences) based on new input data.
- An inference engine is the runtime brain of an AI-enabled system — executing trained models in real-world environments by processing input data and returning intelligent decisions, in real time.
It is the final stage in the ML lifecycle — where models are put to real use in applications, devices, or systems.
Yes, an inference engine is essentially a specialized software stack — designed to execute trained ML models efficiently on target hardware.
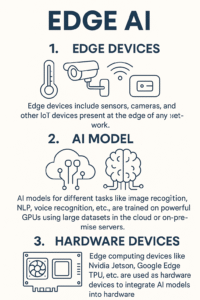
HOW does Edge AI function?
Edge Ai works in two phases:
1. Edge Devices: Edge devices include sensors, cameras, and other IoT devices present at the edge of any network.
2. AI model: AI models for different tasks like image recognition, NLP, voice recognition, etc., are trained on powerful GPUs using large datasets in the cloud or on-premise servers.
3. Hardware devices: Edge computing devices like Nvidia Jetson, Google Edge IPU, etc. are used as hardware devices to integrate AI models into hardware.
How to run AI on Microcontrollers and Microprocessors??
AI is integrated into microcontrollers and microprocessors using Edge AI and TinyML. AI tasks like gesture recognition, object detection, keyword spotting, etc., are performed using these devices.
This integration involves the following steps:
Step 1: Training model
Training deep learning models requires large datasets and powerful GPUs using frameworks like TensorFlow/PyTorch and Keras/Scikit-Learn. This training is done on models based on CNN networks, as briefly discussed here.
Step 2: Optimise model for edge devices.
Due to limited memory in MPUs and MCUs, we need to compress our deep learning models so that they’re compatible enough for the respective embedded hardware devices (edge devices). Techniques like quantisation and pruning are used to reduce the model’s size and computation demands.
Step 3: Convert model for Deployment
The model weights are converted into formats like “.pt,” “.h5,” or “.pb.” This is done to convert into lightweight model formats due to memory limitations.
Step 4: Flash Model onto the Target Hardware
Based on the device type, the models are flashed using TensorFlow Lite (for microcontrollers) and LinuxOS (for microprocessors). The model is exported with the extension “.h” and is embedded into firmware. Hence, an inference code is written using Arduino SDK.
Step 5: Inference running at Edge
Once deployed, the model can start performing inference on the device in real time. It performs AI tasks like classifying sensor readings, recognising voice commands, and detecting faces from a camera stream.
Edge AI Frameworks
LiteRT or Tensorflow Lite
TensorFlow Lite, or LiteRT, is Google’s high-performance runtime for on-device AI. It is used to run a wide variety of AI/ML tasks or convert and run TensorFlow, PyTorch, and JAX models to TFLite format using AI Edge conversion and optimisation tools.
Key Features:
- ODML (Object Detection and Machine Learning ) contraints: LiteRT addressses fie key ODML constraints: Latency, Privacy, Connectivity, size and power consumption of ODML models.
- Mult-Platform support : LiteRT is compatible wth Android, IOS, embedded linux and microcontrollers.
- Multi-framework model options : Models built using tensorflow, Pytorch, amd JAX are converted into FlatBuffers format (.tflite), enablng wide range of SOTA models on LiteRT.
- Diverse Language Support: LiteRT ncludes SDKs for Java/Kotlin, Swift, Objecte-C , C++ and Python.
- High Performance: Hardware acceleration through specialized delegates like GPU and iOS Core ML.
Edge Impulse
It is an end-to-end platform to collect data, train models, optimise, and deploy to devices. Edge Impulse is beginner-friendly and provides drag-and-drop tools and SDKs for C++, Arduino, and Python. It supports TinyML, time series classification, object detection, and keyword spotting.
OpenVINO Toolkit
OpenVINO is built by Intel for computer vision and DL inference acceleration.
It converts models from Tensorflow, ONNX, PyTorch, etc. into an optimised intermediate representation.
It is targeted for Intel CPUs. NCS(Network Control System) and FPGA(Field Programmable Gate Arays) platforms. These are bestfor real-tme vsiion on intel edge hardware.
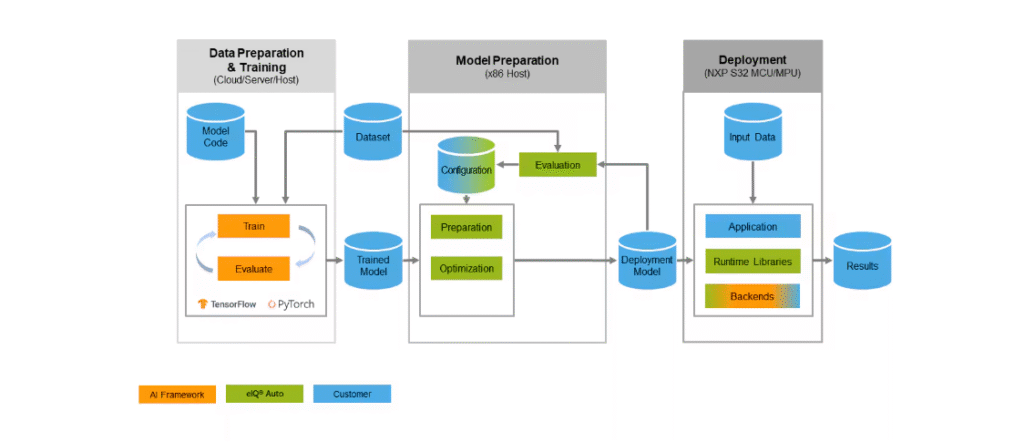
NXP eIQ ML Software Development Environment
It is a full ML SDK (software developer kit) that supports TensorFlow Lite, Glow, Arm CMSIS-NN, and ONNX.
It is an AI software environment that enables the use of ML algorithms on NXP Edgeverse MCUs and MPUs, including i.MX RT crossover MCUs and i.MX family application processors.
An eiq software consists of:
- ML workflow toolkit (eiq toolkit).
- Inference engine.
- Neural network compilers.
- optimised libraries.
NXP’s eIQ supports a wide variety of models varying in domains from audio to vision and miscellaneous. The models performing tasks in these domains form the model zoo at eiq.
Features
- eIQ Autmotive Enablement
- eIQ genAI FLow
- MPU Vision pipelining
ONNX Runtime
Challenges with Edge AI
With a versatile interface for integrating hardware-specific libraries, ONNX Runtime is a cross-platform accelerator for machine learning models. Models from scikit-learn, TFLite, TensorFlow/Keras, PyTorch, and other frameworks can be used with ONNX Runtime.
Machine learning models are powered by ONNX Runtime Inference, Microsoft services, and products like Office, Azure, and Bing.
The following are some instances of ONNX Runtime Inferencing use cases:
1. Boost inference efficiency for a broad range of machine learning models
run on various operating systems and hardware.
2. Develop with Python but implement in a C#, C++, or Java application
3. Utilise models developed in various frameworks to train and carry out inference.
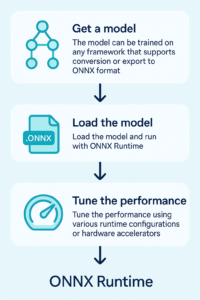
How does it work?
- Get a Model: The model can be trained on any framework that supports conversion or export to ONNX format.
- Load the model and run with ONNX Runtime.
- Tune the performance using various runtime configurations or hardware accelerators.
ONNX Runtime applies a number of graph optimizations on the model graph then partitions it into subgraphs based on available hardware-specific accelerators.
Key challenges for Edge AI are:
- Limited Resources: Edge devices have less computational and processing power. Memory resources are limited too, making it hard to run complex AI models.
- Maintenance Costs: Edge devices at local require constant updating and managing; hence, maintenance costs are increased.
- Maintenance complexity: regular updating and management of distributed devices is complex and time-consuming.
- Security Risks: More devices mean a bigger attack surface, and many lack strong cybersecurity features.
- Data Fragmentation: Local processing can create isolated data silos, making unified analysis harder.
- Integration Issues: Edge AI must work with diverse hardware and legacy systems, leading to compatibility problems.
Advantages of Edge AI
Listed following are a few of the advantages of Edge AI:
- Increased speed of signal transmission.
- Improved reliability.
- Increased scalability.
- Improved net efficiency of the network.
- Improved security.
- Bandwidth and cloud cost reduction.
- Real-time insights/monitoring.
Component's of Edge AI
🚀 Full Edge AI Deployment Workflow
🔹 1. Model Training (Development Phase)
Where: On a PC, workstation, or cloud (e.g., using TensorFlow, PyTorch)
What you do:
Build your neural network
Train it using labeled datasets
Evaluate accuracy, loss, etc.
Output: A trained model file
e.g.,
.pb,.h5,.pt,.onnx, etc.
🔹 2. Model Conversion & Compilation (Optimization Phase)
What this involves:
Model conversion (e.g., from TensorFlow → TFLite or ONNX)
Neural Network Compilation for your target hardware
Optimizations: quantization (FP32 → INT8), pruning, layer fusion, etc.
Hardware mapping: map layers to CPU, NPU, DSP, etc.
Tools used:
TFLite Converter, Arm Vela Compiler, TensorRT, CMSIS-NN Quant Tools, etc.
Output: An optimized, hardware-compatible model
e.g.,
.tflite,.vela,.engine, C arrays
🔹 3. Model Deployment & Inference (Runtime Phase)
Where: On the target Edge device (MCU, MPU, embedded board)
What happens:
The inference engine loads the compiled model
It takes real-world input (sensor, camera, etc.)
Runs inference and gives prediction/output
Inference engines used:
TensorFlow Lite Runtime, CMSIS-NN, Ethos-U Runtime, ONNX Runtime
Inference Engine ( 3rd stage):
🧠 What is an Inference Engine?
An inference engine is a software runtime environment that executes a trained and compiled machine learning model to produce predictions (also called inferences) based on new input data.
It is the final stage in the ML lifecycle — where models are put to real use in applications, devices, or systems.
⚙️ Core Functions of an Inference Engine
Function Description Model Loading Loads the optimized/compiled model into memory (e.g., TFLite, ONNX, proprietary binary) Input Preprocessing Transforms raw inputs (images, sensor data) into model-ready tensors (resize, normalize, reshape, etc.) Model Execution Runs forward-pass computation (e.g., matrix multiplications, activations, convolutions) Output Postprocessing Converts model outputs into useful format (e.g., class label, bounding boxes, confidence score) Hardware Acceleration Uses available compute resources — CPU, GPU, NPU, DSP, FPGA, or MCU — to optimize speed and power efficiency 📦 Architecture of an Inference Engine
pgsql+------------------+
Input → | Preprocessing |
+------------------+
| Model Execution | ← Run on optimized kernels (CPU/GPU/NPU)
+------------------+
Output ← | Postprocessing |
+------------------+
It may also include modules for:
Memory management (tensor allocation)
Delegate systems (e.g., NNAPI, GPU delegate in TFLite)
Model caching or dynamic shape handling
📌 Example Inference Engines (Runtime Libraries)
Engine Best For Format Supported Hardware TensorFlow Lite Mobile, Embedded .tfliteCPU, GPU, NPU (Edge TPUs) ONNX Runtime Cross-platform .onnxCPU, GPU TensorRT NVIDIA .onnx,.engineNVIDIA GPU OpenVINO Runtime Intel .xml+.binIntel CPU, VPU CMSIS-NN Cortex-M MCUs C code CPU Ethos-U Runtime Cortex-M + NPU Binary (via Vela) Arm NPU ✅ Key Takeaway:
Yes — these inference engines are software libraries built to:
The inference engines listed in that table are all software libraries or runtime frameworks that are:
Compatible with specific model formats (e.g.,
.tflite,.onnx,.bin)Designed and optimized to run on specific hardware platforms (e.g., CPU, GPU, NPU, DSP, MCU)
Run on specific hardware platforms,
Neural Network Compiler?( 2nd stage)
🧠 What is a Neural Network Compiler?
A Neural Network Compiler is a specialized toolchain that transforms a trained ML model into an optimized format or binary that can run efficiently on specific hardware — such as CPUs, GPUs, NPUs, or microcontrollers.
🔁 Think of it like a Software Compiler
Just as a C compiler converts human-readable code into machine code optimized for a processor, a neural network compiler converts a trained model into a hardware-optimized representation.
📦 Input and Output of a Compiler
| Component | Description |
|---|---|
| Input | Trained ML model (e.g., .pb, .onnx, .tflite) |
| Output | Optimized binary or model file (.bin, .tflite, .engine, C-array) for specific inference engine or hardware |
🔧 Popular Neural Network Compilers – Full Breakdown
| Compiler | Works With (Input) | Target Hardware | Output Format |
|---|---|---|---|
| TVM (Apache) | TensorFlow, PyTorch, ONNX models | CPU, GPU, FPGA, NPU | TVM runtime binary or shared object (e.g., .so, .dll) |
| XLA (Google) | TensorFlow graphs (.pb, SavedModel) | TPU, CPU, GPU | HLO IR (High-Level Optimizer Intermediate Representation) |
| TensorRT Compiler | TensorFlow (.pb), ONNX (.onnx) | NVIDIA GPUs (Jetson, RTX, etc.) | Serialized .engine file (TensorRT optimized binary) |
| TFLite Converter | TensorFlow models (SavedModel, .pb) | Edge devices: Mobile, MCU, Edge TPU | .tflite (lightweight FlatBuffer format) |
| Arm Vela Compiler | .tflite models | Arm Ethos-U NPU (with Cortex-M) | Compiled binary (.vela) |
| OpenVINO Model Optimizer | ONNX, TensorFlow (.pb) | Intel CPU, VPU (Myriad X) | .xml (IR structure) + .bin (weights) |
| Glow (Meta) | PyTorch (scripted/traced models) | CPU, GPU | LLVM IR or optimized Glow IR |
| CMSIS-NN Quant Tools | Quantized TFLite or TensorFlow Lite Micro models | Arm Cortex-M MCUs | C arrays or CMSIS-NN compatible C code (e.g., .c, .h) |
EiQ Portal
There are 2 approaches available with the eIQ Toolkit, based on what the user provides and what the
expectations are. The following approaches are referred to throughout this document:
• Bring Your Own Data (BYOD) – you bring image data, use the eIQ Toolkit to develop your own model, and
deploy it on the target.
• Bring Your Own Model (BYOM) – you bring a pretrained model and use the eIQ Toolkit for optimization,
deployment, or profiling
The eIQ Portal is a GUI that allows the user to leverage the eIQ Toolkit capabilities in a practical and intuitive
manner. With little or no knowledge of machine learning, the eIQ Portal enables the user to build models for
image classification, segmentation, and object-detection problems.
- To do practical handson of eiq portal for BYOD and for BYOM both
- To specificall build a BYOD and BYOM for segemntation
EiQ Model Zoo
Model Tool is the key component of the Bring Your Own Model
workflow. It allows you to view, profile, convert,
or modify pretrained models. Models can run on the local machine or on a remote device. You can either open
Model Tool and then load your model or open the model after training using eIQ Portal as follows
The NXP eIQ® Model Zoo offers pre-trained models for a variety of domains and tasks that are ready to be deployed on supported products.
Models are included in the form of “recipes” that convert the original models to TensorFlow Lite format. This allows users to find the original re-trainable versions of the models, allowing fine-tuning/training if required.
✅ Yes, the eIQ Model Zoo is used in the Model Development stage. It provides pre-trained models so you can skip training and go straight to compiling and deploying.
You can use these models:
As-is (if they fit your use case)
Or fine-tune/retrain them (transfer learning) before compiling
TensorFlow Lite is an inference engine!!!
The NXP eIQ® Model Zoo is structured in the following way: Main Page -> Domain -> Task -> Model.
Multiple models may be proposed for the same task. Each model has its own information page.